Podcast 1:7 - History and Future of Data Center Architectures
10/29/19 • 21 min
In this episode, the history of data center architecture and application development is reviewed, and the trends of application development shaping the data center of the future. Find out how containers, serverless, and data mesh architectures are being leveraged to decrease deployment times and increase reliability.
Purpose Built Hardware-software Stacks
- Build Hardware based on software stack requirements.
- Long Development Times
- No re-use of technology
- Technology moves too fast
- Hard to integrate with other applications
- Creates technical debt
Virtualization Architectures
- 20 years old technology (VMWare, KVM, HyperV)
- Common Hardware re-use
- Decrease Cost
- Security concerns increase
- Noisy neighbors
Cloud Architectures
- Abstract and simplify Operations
- Common Hardware re-use
- Decrease Cost OpEx and CapEx
- Bursting ability
- Security concerns increase
- Noisy neighbors
- Integration costs
Service and Container Architectures
- Automatic deployment across Clouds
- Optimized OpEx and CapEx
- Fault tolerance
- Easier Integration
- Security concerns increase
- Increased complexity
- Where’s my data
Internet of Things Architectures
- Increase the amount of Data
- Visibility increases
- Security concerns increase
- Increased complexity
- Where’s my data
Data and Information Management Architectures
- Automatic data management
- Data Locality
- Data Governance
- Security concerns increase
- Classification Profiles Not supported
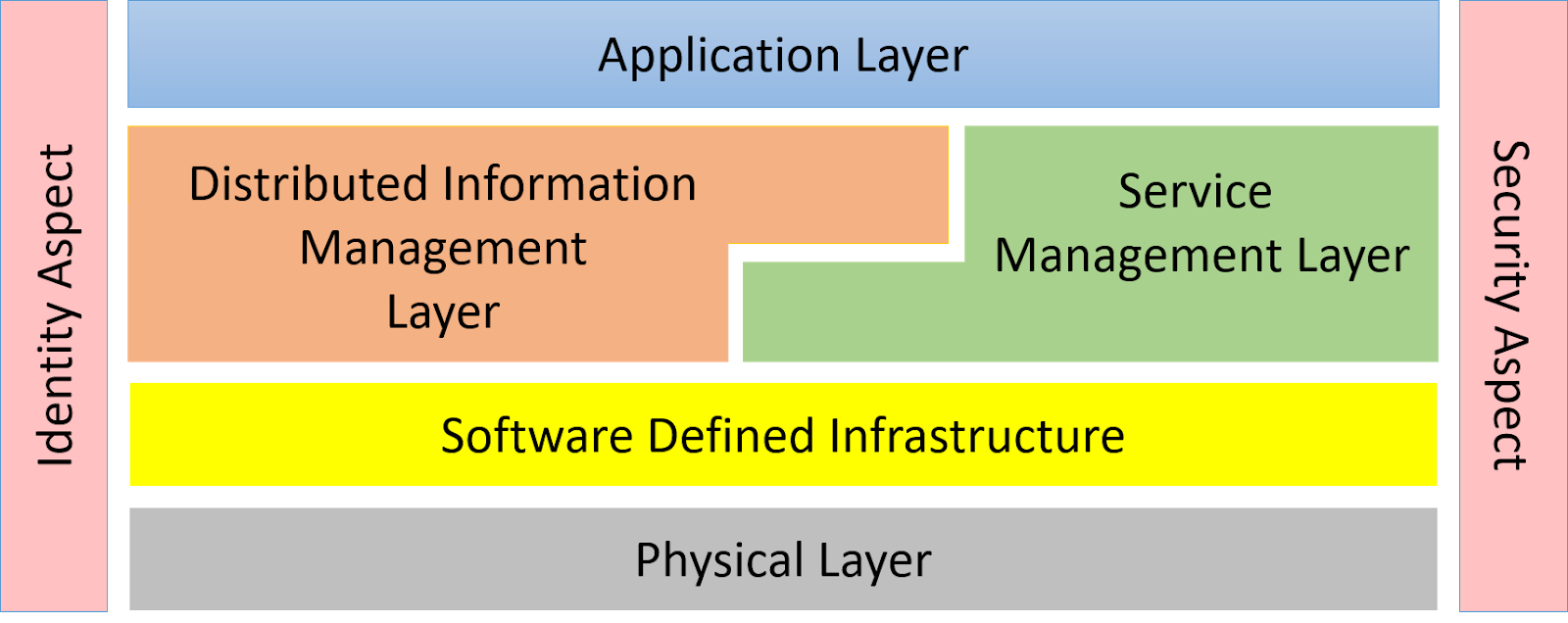
Security and Identity Aspects
- Common Identity (People, Devices, Software)
- Access, Authorization, Authentication
- Detect attacks throughout the ecosystem
- Establish root of trust from through the stack
- Quarantine with reliability
In this episode, the history of data center architecture and application development is reviewed, and the trends of application development shaping the data center of the future. Find out how containers, serverless, and data mesh architectures are being leveraged to decrease deployment times and increase reliability.
Purpose Built Hardware-software Stacks
- Build Hardware based on software stack requirements.
- Long Development Times
- No re-use of technology
- Technology moves too fast
- Hard to integrate with other applications
- Creates technical debt
Virtualization Architectures
- 20 years old technology (VMWare, KVM, HyperV)
- Common Hardware re-use
- Decrease Cost
- Security concerns increase
- Noisy neighbors
Cloud Architectures
- Abstract and simplify Operations
- Common Hardware re-use
- Decrease Cost OpEx and CapEx
- Bursting ability
- Security concerns increase
- Noisy neighbors
- Integration costs
Service and Container Architectures
- Automatic deployment across Clouds
- Optimized OpEx and CapEx
- Fault tolerance
- Easier Integration
- Security concerns increase
- Increased complexity
- Where’s my data
Internet of Things Architectures
- Increase the amount of Data
- Visibility increases
- Security concerns increase
- Increased complexity
- Where’s my data
Data and Information Management Architectures
- Automatic data management
- Data Locality
- Data Governance
- Security concerns increase
- Classification Profiles Not supported
Security and Identity Aspects
- Common Identity (People, Devices, Software)
- Access, Authorization, Authentication
- Detect attacks throughout the ecosystem
- Establish root of trust from through the stack
- Quarantine with reliability
Previous Episode

Podcast 1:6 - Elastic Search + Optane DCPMM = 2x Performance
Intel Optane DC Persistent Memory to the reuse
Intel's new Persistent Memory technology has three modes of operation. One as an extension of your current memory. Imagine extending your server with 9TBytes of Memory. The second is called AppDirect mode where you can use the Persistent Memory as a persistent segment of memory or as a high-speed SSD. The third mode is called mix mode. In this mode, a percentage of the persistent memory is used for AppDirect and the other to extend your standard DDR4 Memory. When exploring this new technology, I realized that I could take the persistent memory and use it as a high-speed SSD. If I did that could I increase the throughput of my ElasticSearch Server? So I set up a test suite to try this out.
Hardware Setup and configuration
1. Physically configure the memory
• 2-2-2 configuration is the faster configuration for using the Apache Pass Modules.
2. Upgrade the BIOS with the latest updates
3. Install supported OS
• ESXi6.7+
• Fedora29+
• SUSE15+
• WinRS5+
4. Configure the Persistent Memory for 100% AppDirect Mode to get maximum storage
# ipmctl create -goal MemoryMode=0 PersistentMemoryType=AppDirect# reboot
# ipmctl show -region
# ndctl list -Ru
[
{
"dev":"region1",
"size":"576.00 GiB (618.48 GB)",
"available_size":"576.00 GiB (618.48 GB)",
"type":"ElasticSearch",
"numa_node":1,
"iset_id":"0xe7f04ac404a6f6f0",
"persistence_domain":"unknown"
},
{
"dev":"region0",
"size":"576.00 GiB (618.48 GB)",
"available_size":"576.00 GiB (618.48 GB)",
"type":"ElasticSearch",
"numa_node":0,
"iset_id":"0xf5484ac4dfaaf6f0",
"persistence_domain":"unknown"
}
]
# ndctl create-namespace -r region0 --mode=sector
# ndctl create-namespace -r region1 --mode=sector
5. Now create the filesystem Create the FileSystem
# mkfs.xfs /dev/ElasticSearch0s# mkfs.xfs /dev/ElasticSearch1s
# mkdir /mnt/ElasticSearch0s
# mkdir /mnt/ElasticSearch1s
# mount /dev/ElasticSearch0s /mnt/ElasticSearch0s
# mount /dev/ElasticSearch1s /mnt/ElasticSearch1s
Now that you should be able to access the filesystems via /mnt/ElasticSearch0s and /mnt/ElasticSearch1s.
Setup and configuration
We chose to evaluate the performance and resiliency of ElasticSearch using off the shelf tools. One of the most used performance test suites for ElasticSearch is ESRally. ESRally was developed by the makers of ElasticSearch and is easy to set up and run. It comes with its nomenclature that is easy to pick up.
• Tracks - Test Cases are stored in this directory.
• Cars – configuration files to be used against the distributions
• Race – This contains the data, index, and log files for ElasticSearch run. Each run has a separate directory.
• Distributions – ElasticSearch installations
• Data – data used for the tests
• Logs – logs for ESRally not for ElasticSearch.
ESRally can attach to a specific ElasticSearch cluster, or it can be configured to install and run a standard release of ElasticSearch on the fly, stored in the distribution directory. When I was looking at what directories to move between a PMEM drive and a SATA drive, I looked at the race directory. I found out that I would be limited by the data directory and log directory as well. So I decided to move the complete .rally directory between the two drives.
ESRally Pre-requisites
• Python 3.5+ which includes pip3.
• Java JDK 1.8+
Software Installation
ESRally can be installed from GitHub repository. See http://ESRally.readthedocs.io for more information.
To install ESRally, use the pip3 utility. Pip3 is installed when you install python 3.5.
# pip3 install ESRallyNow you want to configure ESRally
# export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk# ESRally configure
ESRally config creates a “.rally” directory in your home directory. This “.rally” directory is used to store all of the tests, data, and indices.
Next, you need to install the eventdata track. https://github.com/elastic/rally-eventdata-track
This track generates about 1.8 TBytes of traffic through ElasticSearch. It is a good test because much is the data is generated and not read from a drive, which means you are not limited by another drive’s performance and you can test the raw performance of the different drives with ElasticSearch. Total storage used is about 200GBytes.
Running Tests (Races)
Next, you run the tests for the different configurations. First, I run the following test a...
Next Episode
Podcast 1:8 - The John Henry of AI
John Henry (Wikipedia) - Talcott West Virginia
The tall tale of John Henry is just as endearing now as is was 170 years ago when the story started. Machine vs Man. (Think Skynet and Terminator). As we are at the beginning of another industrial revolution (Industry 4.0) many people are concerned that AI will take their jobs. Just like steam power took the jobs of thousands of railroad workers in the 1800s. In this episode, we explore the changes in workforces and effecting change in such an environment.
Story of John Henry
- Dawn of the Industry 2.0
- Several sites claim to be the site of the tunnel that was the location of the race between man and machine.
- Big Bend Tunnel - West Virginia
- Lewis Tunnel - Virginia
- Coosa Mountain Tunnel - Alabama
- The Story -
- John Henry was born with a Hammer in his hand.
- He was the strongest man that ever lived.
- Started helping the railroad works by carrying rocks at age 6
- By age 10 he was working a hard steel drill.
- By the time he was a young man, he was the best steel driver that ever lived.
- Big tunnel needed to be dug through the side of a mountain. 1 mile long.
- A "Technologist" shows up with a steam drill to show the latest in technology.
- The race between John Henry and the steam drill ensued.
- John Henry won the race working all day and all night
- The next day John Henry died from exhaustion.
- The Movie - The Rock will play John Henry in a Netflix original. And Terry Crews in another competing version.
- The Song - Johnny Cash
History repeats itself
- Industry 3.0 - Information Technology Emergence. Computers begin to take over jobs. New jobs are created.
- Industry 4.0 - AI starts taking over information workers' jobs, agriculture jobs, and manufacturing jobs.
- Understand the story of John Henry. From the perspective of the automated drill manufacturer.
- How do you find John Henry in your organization? How can you go about not having the same thing happen to you and your organization?
- Culture Keepers -
- What motivates them,
- Are they afraid of losing their jobs?
- Their careers?
- How far along are they in their careers?
- Can they be retrained?
- Change Agents -
- How do you motivate them? Most of the time they want to be disruptive.
- How do you empower them?
- How do you incentivize others to follow them?
- Followers - Go with the flow. Don't make waves.
Links
- https://en.wikipedia.org/wiki/John_Henry_(folklore)
- https://www.wideopencountry.com/american-tall-tales-can-teach-life/
- https://www.npr.org/2013/12/20/255721505/manufacturing-2-0-old-industry-creating-new-high-tech-jobs
- https://supplychaingamechanger.com/the-industrial-revolution-from-industry-1-0-to-industry-5-0/
If you like this episode you’ll love





{kind=link}
Episode Comments
Generate a badge
Get a badge for your website that links back to this episode
<a href="https://goodpods.com/podcasts/rise-of-the-stack-developer-118314/podcast-17-history-and-future-of-data-center-architectures-6039425"> <img src="https://storage.googleapis.com/goodpods-images-bucket/badges/generic-badge-1.svg" alt="listen to podcast 1:7 - history and future of data center architectures on goodpods" style="width: 225px" /> </a>
Copy