Rise of the Stack Developer
Darren Pulsipher
All episodes
Best episodes
Top 10 Rise of the Stack Developer Episodes
Goodpods has curated a list of the 10 best Rise of the Stack Developer episodes, ranked by the number of listens and likes each episode have garnered from our listeners. If you are listening to Rise of the Stack Developer for the first time, there's no better place to start than with one of these standout episodes. If you are a fan of the show, vote for your favorite Rise of the Stack Developer episode by adding your comments to the episode page.
Episode 1:5 - Information Management Maturity Model
Rise of the Stack Developer
08/29/19 • 15 min
Developing a Data Strategy can be difficult, especially if you don’t know where your current organization is and where it wants to go. The Information Management Maturity Model helps CDOs and CIOs find out where they currently are in their Information Management journey and their trajectory. This map helps guide organizations as they continuously improve and progress to the ultimate data organization that allows them to derive maximum business value from their data.
The model can be seen as a series of phases, starting from least mature to most mature: Standardized, Managed, Governed, Optimized, and Innovation. Many times an organization can exist in multiple phases at the same time. Look for where the majority of your organization operates, and then identify your trail-blazers that should be further along in maturity. Use your Trail-blazers to pilot or prototype new processes, technologies or organizational structures.
Standardized Phase
The standardized phase has three sub-phases. Basic, Centralized, and Simplified. Most organizations find them self somewhere in this phase of maturity. Look at the behaviors, technology, and processes that you see in your organization to find where you fit.
Basic
Almost every organization fits into this phase, at least partially. Here data is only used reactively and in an ad hoc manner. Additionally, almost all the data collected is stored based on predetermined time frames (often “forever”). Companies in BASIC do not erase data for fear of missing out on some critical information in the future. Attributes that best describe this phase are:
- Management by Reaction
- Uncatalogued Data
- Store Everything Everywhere
Centralized (Data Collection Centralized)
As organizations begin to evaluate data strategy they first look at centralizing their storage into large Big Data Storage solutions. This approach takes the form of Cloud storage or on-prem big data appliances. Once the data is collected in a centralized location Data Warehouse technology can be used to enable basic business analytics for the derivation of actionable information. Most of the time this data is used to fix problems with customers, supply chain, product development, or any other area in your organization where data is generated and collected. The attributes that best describe this phase are:
- Management by Reaction
- Basic Data Collection
- Data Warehouses
- Big Data Storage
Simplified
As the number of data sources increase in an organization, companies begin to form organizations that focus on data strategy, organization and governance. This shift begins with a Chief Data Officer’s (CDO) office. There are several debates on where the CDO fits in the company, under the CEO or CIO. Don’t get hung up on where they sit in the organization. The important thing is to establish a data organization focus and implement a plan for data normalization. Normalization gives the ability to correlate different data sources to gather new insight into what is going on across your entire company. Note without normalization, the data remains siloed and only partially accessible. Another key attribute of this phase is the need to develop a plan to handle sheer, the massive volume of data being collected. Because of the increase in volume and cost of storing this data, tiered storage becomes important. Note that in the early stages it is almost impossible to know the optimal way to manage data storage. We recommend using the best information available to develop rational data storage plans, but with the cavett that this will need to be reviewed and improved once the data is being used. The attributes that best describe this phase are:
- Predictive Data Management (Beginning of a Data-Centric Organization)
- Data Normalization
- Centralized Tiered Storage
Managed (Standard Data Profiles)
At this phase organizations have formalized their data organization and have segmented the different roles in the data organization: Data Scientist, Data Stewards, Data Engineers are now on the team and have defined roles and responsibilities. Meta-Data Management becomes a key factor in success at this phase, and multiple applications can now take advantage of the data in the company. Movement from a Data Warehouse to a Data Lake has taken place to allow for more agility in development of data-centric applications. Data Storage has been virtualized to allow for a more efficient and dynamic Storage solution. Data Analytics can now run on data sets from multiple sources and departments in the company. These attributes best describe this phase:
- Organized Data Management (Data Org in place with key roles identified)
- Meta-Data Management
- Data Lineage <...
Rise of the Stack Developer History
Rise of the Stack Developer
05/06/19 • 19 min
System Admin - 2002
Stack Developer - 2019
System Administration, Configuration Management, Build Engineer, and DevOps many of the same responsibilities but over the years the names have changed. Listen as Darren Pulsipher gives a brief history of his journey through the software and product development over the last four decades and how so much has changed and much has remained the same.
Darren’s History
- Started as a Software Programmer
- Had Linux and Unix Experience
- Tell Story of Mimi Larson getting me an AT&T Unix box and a manual in 1985
- Worked as a System Administrator in College (AIX, HPUX, VMS, SunOS, Solaris, Xwindows)
- Always designated as the software developer that would do the build at night.
- Learned about SCCS and the newer RCS at my first job.
- Quickly become the configuration management grunt.
- Changes in Version Control Systems and Build systems began to collide with each other.
- Client-Server tools arose and started being spread across multiple machines. The rise of the Concurrent Version System. (CVS and tools like ClearCase)
- For you young bucks you have probably heard of ClearCase, but it was my money tree for about 10 years. The black art of ClearCase administration was my sweet spot.
- ClearCase really brought build and configuration management together with build avoidance and management of derived objects and binaries for the first time.
- Then can truly distributed, de-centralized, simplified tools like git, mercurial. Convention over configurability made these tools easier to use and the Configuration Management engineering job shifted again. Focused on more build systems and Continuous Integration and Delivery.
- The DevOps Engineer was born.
- As development cycles decreased and build cycle times when from days to hours to minutes. Development teams took a more dynamic and Release-break-fix mentality.
- Now with microservices, containers and serverless, a new role is starting to emerge.
- The Stack Developer.
- develop new stacks of services across multiple environments (Local, Dev, Build, Test, and Production)
- These stacks can be made of multiple services and microservices.
- Talk about a stack being different in the different environments.
- Simple Mean stack first.
- Local. One mongo instance, One nodejs worker node
- Dev. One Mongo Instance, Multiple NodeJS worker nodes.
- Build. Build environment might be completely different.
- Test. Multiple instances of the same product with additional services for performance testing, logging, debug turned on, etc..
- Production. Backup, Fault tolerance, etc...
- Creating these re-usable stack gives developers the ability to develop applications and not worry about system administration tasks.

Podcast 1:6 - Elastic Search + Optane DCPMM = 2x Performance
Rise of the Stack Developer
09/13/19 • 16 min
Intel Optane DC Persistent Memory to the reuse
Intel's new Persistent Memory technology has three modes of operation. One as an extension of your current memory. Imagine extending your server with 9TBytes of Memory. The second is called AppDirect mode where you can use the Persistent Memory as a persistent segment of memory or as a high-speed SSD. The third mode is called mix mode. In this mode, a percentage of the persistent memory is used for AppDirect and the other to extend your standard DDR4 Memory. When exploring this new technology, I realized that I could take the persistent memory and use it as a high-speed SSD. If I did that could I increase the throughput of my ElasticSearch Server? So I set up a test suite to try this out.
Hardware Setup and configuration
1. Physically configure the memory
• 2-2-2 configuration is the faster configuration for using the Apache Pass Modules.
2. Upgrade the BIOS with the latest updates
3. Install supported OS
• ESXi6.7+
• Fedora29+
• SUSE15+
• WinRS5+
4. Configure the Persistent Memory for 100% AppDirect Mode to get maximum storage
# ipmctl create -goal MemoryMode=0 PersistentMemoryType=AppDirect# reboot
# ipmctl show -region
# ndctl list -Ru
[
{
"dev":"region1",
"size":"576.00 GiB (618.48 GB)",
"available_size":"576.00 GiB (618.48 GB)",
"type":"ElasticSearch",
"numa_node":1,
"iset_id":"0xe7f04ac404a6f6f0",
"persistence_domain":"unknown"
},
{
"dev":"region0",
"size":"576.00 GiB (618.48 GB)",
"available_size":"576.00 GiB (618.48 GB)",
"type":"ElasticSearch",
"numa_node":0,
"iset_id":"0xf5484ac4dfaaf6f0",
"persistence_domain":"unknown"
}
]
# ndctl create-namespace -r region0 --mode=sector
# ndctl create-namespace -r region1 --mode=sector
5. Now create the filesystem Create the FileSystem
# mkfs.xfs /dev/ElasticSearch0s# mkfs.xfs /dev/ElasticSearch1s
# mkdir /mnt/ElasticSearch0s
# mkdir /mnt/ElasticSearch1s
# mount /dev/ElasticSearch0s /mnt/ElasticSearch0s
# mount /dev/ElasticSearch1s /mnt/ElasticSearch1s
Now that you should be able to access the filesystems via /mnt/ElasticSearch0s and /mnt/ElasticSearch1s.
Setup and configuration
We chose to evaluate the performance and resiliency of ElasticSearch using off the shelf tools. One of the most used performance test suites for ElasticSearch is ESRally. ESRally was developed by the makers of ElasticSearch and is easy to set up and run. It comes with its nomenclature that is easy to pick up.
• Tracks - Test Cases are stored in this directory.
• Cars – configuration files to be used against the distributions
• Race – This contains the data, index, and log files for ElasticSearch run. Each run has a separate directory.
• Distributions – ElasticSearch installations
• Data – data used for the tests
• Logs – logs for ESRally not for ElasticSearch.
ESRally can attach to a specific ElasticSearch cluster, or it can be configured to install and run a standard release of ElasticSearch on the fly, stored in the distribution directory. When I was looking at what directories to move between a PMEM drive and a SATA drive, I looked at the race directory. I found out that I would be limited by the data directory and log directory as well. So I decided to move the complete .rally directory between the two drives.
ESRally Pre-requisites
• Python 3.5+ which includes pip3.
• Java JDK 1.8+
Software Installation
ESRally can be installed from GitHub repository. See http://ESRally.readthedocs.io for more information.
To install ESRally, use the pip3 utility. Pip3 is installed when you install python 3.5.
# pip3 install ESRallyNow you want to configure ESRally
# export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk# ESRally configure
ESRally config creates a “.rally” directory in your home directory. This “.rally” directory is used to store all of the tests, data, and indices.
Next, you need to install the eventdata track. https://github.com/elastic/rally-eventdata-track
This track generates about 1.8 TBytes of traffic through ElasticSearch. It is a good test because much is the data is generated and not read from a drive, which means you are not limited by another drive’s performance and you can test the raw performance of the different drives with ElasticSearch. Total storage used is about 200GBytes.
Running Tests (Races)
Next, you run the tests for the different configurations. First, I run the following test a...
Podcast 1:3 - Decreasing Ingestion Congestion with Optane DCPMM
Rise of the Stack Developer
07/31/19 • 31 min
Big Data analytics needs data to be valuable. Collecting data from different machines, IoT devices, or sensors is the first step to being able to derive value from data. Ingesting data with Kafka is a common method used to collect this data. Find out how using Intel's Optane DC Persistent Memory to decrease ingestion congestion and increase total thruput of your ingestion solution.
Kafka in real examples
- Ingestion is the first step in getting data into your data lake, or data warehouse
- Kafka is basically a highly available distributed PubSubHub.
- Data from a producer is published on Kafka Topics which consumers subscribe to. Topics give the ability segment the data for ingestion.
- Topics can be spread over a set of servers on different physical devices to increase reliability and thruput.
- Performance Best Practices
- Buffer Size of the Producers should be a multiple of the message size
- Batch Size can be changed based on the message size for optimal performance
- Spread Logs for partitions across multiple drives or on fast drives.
- Example Configuration (LinkedIn)
- 13 million messages per second, (2.75 GB/s)
- 1100 Kafka brokers organized into more than 60 clusters.
- Automotive Space
- One Customer has 100 Million Cars - 240KB/min/car
- 1.6 Million Messages/sec
- 800 GB/s
- Approximate size of the installation
- 4400 Brokers, over 240 Clusters.
- One Customer has 100 Million Cars - 240KB/min/car
Optane DC Persistent Memory
- Ability to use Optane technology in a DDR4 DIMM form factor.
- 128GB, 256 GB, 512GB PMMs are available. Up to 3 TB per socket
- Two modes of operation: App Direct Mode, and Memory Mode.
- Memory Mode gives the ability to have cheaper memory than typical DDR4 prices at a fraction of the cost.
- App Direct Mode means you can write a program to write directly to memory and it is persistent. Survives over reboots or power loss.
- App Direct Mode can also be used to create ultra-fast filesystems with memory drives.
- DCPMM uses DDR4 memory and DCPMM in a mixed mode. Example a 16G DIMM paired with a 128G PMM. or a 64G DIMM Paired with a 512GB PMM.
- Memory modes can be controlled in the Bios of from the linux kernel.
- ipmctl - utility for configuring and managing Intel Optane DC persistent memory modules (PMM).
- ndctl – utility for managing (non-volatile memory device) sub-system in the Linux kernel
Improving Ingestion using Persistent Memory
- Use Larger Memory Footprint for more kafa servers on the same machine with larger Heap Space
- Change Kafka to write directly to Persistent Memory
- Create a Persistent Memory Filesystem and point kafka logs to the new filesystem
Testing Results
- Isolate performance variability by limiting the testing to one broker on the same machine as the producer.
- Remove network variability and bottleneck of the network.
- Decrease inter-broker communication and replica bottlenecks
- Only producer is run to find the maximum that can be ingested.
- Only Consumers are run to find the maximum that can be egressed.
- Mixed Producer and Consumer are run to find passthru rates.
- First approach. 50% persistent memory in App Direct Mode
- 3x performance over Sata Drive mounted log files
- 2x performance over Optance NVMe drives
- Second approach. 100% persistent memory in App Direct Mode
- 10x performance over Sata Drive mounted log files.
- approximately ~2 Giga Bytes per second. over 150 MB/sec for SATA drive
- Additional testing has been performed with Cluster to increase total thruput and we found we were limited not by the drive speed which is normally the case, but by the network speed. We were limited to 10 G bit network.
Podcast 1:8 - The John Henry of AI
Rise of the Stack Developer
11/05/19 • 17 min
John Henry (Wikipedia) - Talcott West Virginia
The tall tale of John Henry is just as endearing now as is was 170 years ago when the story started. Machine vs Man. (Think Skynet and Terminator). As we are at the beginning of another industrial revolution (Industry 4.0) many people are concerned that AI will take their jobs. Just like steam power took the jobs of thousands of railroad workers in the 1800s. In this episode, we explore the changes in workforces and effecting change in such an environment.
Story of John Henry
- Dawn of the Industry 2.0
- Several sites claim to be the site of the tunnel that was the location of the race between man and machine.
- Big Bend Tunnel - West Virginia
- Lewis Tunnel - Virginia
- Coosa Mountain Tunnel - Alabama
- The Story -
- John Henry was born with a Hammer in his hand.
- He was the strongest man that ever lived.
- Started helping the railroad works by carrying rocks at age 6
- By age 10 he was working a hard steel drill.
- By the time he was a young man, he was the best steel driver that ever lived.
- Big tunnel needed to be dug through the side of a mountain. 1 mile long.
- A "Technologist" shows up with a steam drill to show the latest in technology.
- The race between John Henry and the steam drill ensued.
- John Henry won the race working all day and all night
- The next day John Henry died from exhaustion.
- The Movie - The Rock will play John Henry in a Netflix original. And Terry Crews in another competing version.
- The Song - Johnny Cash
History repeats itself
- Industry 3.0 - Information Technology Emergence. Computers begin to take over jobs. New jobs are created.
- Industry 4.0 - AI starts taking over information workers' jobs, agriculture jobs, and manufacturing jobs.
- Understand the story of John Henry. From the perspective of the automated drill manufacturer.
- How do you find John Henry in your organization? How can you go about not having the same thing happen to you and your organization?
- Culture Keepers -
- What motivates them,
- Are they afraid of losing their jobs?
- Their careers?
- How far along are they in their careers?
- Can they be retrained?
- Change Agents -
- How do you motivate them? Most of the time they want to be disruptive.
- How do you empower them?
- How do you incentivize others to follow them?
- Followers - Go with the flow. Don't make waves.
Links
- https://en.wikipedia.org/wiki/John_Henry_(folklore)
- https://www.wideopencountry.com/american-tall-tales-can-teach-life/
- https://www.npr.org/2013/12/20/255721505/manufacturing-2-0-old-industry-creating-new-high-tech-jobs
- https://supplychaingamechanger.com/the-industrial-revolution-from-industry-1-0-to-industry-5-0/
Episode 1:4 - History of Data Architecture
Rise of the Stack Developer
08/08/19 • 26 min
{kind=link}
Organizations are looking to their vast data stores for nuggets of information that give them a leg up on their competition. “Big Data Analytics” and Artificial Intelligence are the technologies promising to find those gold nuggets. Mining data is accomplished through a “Distributed Data Lake Architecture” that enables cleansing, linking, and analytics of varied distributed data sources.
Ad Hoc Data Management
- Data is generated in several locations in your organization.
- IoT (Edge Devices) has increased the number of locations and types of data that have grown.
- Organizations typically look at the data sources individually and application-centric.
- Data Scientists look at a data source and create value from it. One application at a time.
- Understanding the data and normalizing it is key to making this successful. (A zip code is a zip code, a phone number has multiple formats, Longitude, Latitude)
- Overhead of creating a Data-Centric Application is high if you start from scratch.
- People begin using repeatable applications to get the benefits of reuse.
Data Warehouse Architecture
- Data Warehouse architecture takes repeatable processes to the next level. Data is cleansed, linked, and normalized against a standard schema.
- Data is cleansed once and used several times, with different applications.
- Benefits include:
- Decrease time to answer.
- Increase reusability
- A decrease in Capital Cost
- Increase in Reliability
Data Lake Architecture
- A Data Lake moves all of the data and stores all of the data in its raw format.
- Data Lake Architecture uses Meta-Data to better understand the data.
- Allows for late binding of applications to the data.
- Gives the ability to use/see the data in different ways for different applications.
- Benefits include:
- Ability to reuse data for more than one purpose
- Decrease time to create new applications
- Increase the reusability of data
- Increase Data Governance (Security and Compliance)
Distributed Data Lake (Data Mesh)
- One of the biggest problems with Data Lake and Data Warehouse is the movement of data.
- As data volume goes up, so does its gravity. It becomes harder to move.
- Regulations can limit where the data can actually reside.
- Edge devices that have data need to encrypt and manage data on edge devices before pushing to a data lake.
- This architecture allows for data services to be pushed to compute elements into the edge. Including storage, encryption, cleanse, link, etc..
- Data is only moved to a centralized location based on policy and data governance.
- Each application developed does not need to know where the data is located. The architecture handles that for them.
- Benefits include:
- Decrease time to answer.
- Late data binding to runtime.
- Multiple applications running on the same data in the same devices
- Decrease cost due to decrease movement of data.
Rise of the Stack Developer (ROSD) - DWP
Podcast 1:2 - Legacy integration with Robotic Process Automation
Rise of the Stack Developer
07/27/19 • 28 min
One of the growing areas to help with Legacy Integration and automation of integration is the use of automation tools and frameworks. Over the last 3 years, a significant emphasis on the automation of workflows with legacy and new cloud-aware applications for information workers has emerged. These tools sets are called Robotic Process Automation (RPA) tools.
Robotic Process Automation (RPA)
What RPAs are NOT
- A method to control and manage Robots
- Process automation for factory machines
- A way of replacing workers
What RPAs are
- A way of automating Information Workers redundant tasks
- A set of tools that records how Users interact with applications and plays it back
- A way to decrease errors in highly repetitive, user interface intensive Tasks
Current Market Place – 2019
- UiPath - $1 Billion investment on $300 Million in Annual Revenue
- Automation Anywhere - $500 Million investment on $100 Million in Annual Revenue
- BluePrism - $50 Million investment on $30 Million in Annual Revenue
Place where RPA works well
- Financial Institutions
- Medical Field
- Insurance
- Any place where lots of Information Workers do highly repetitive manual tasks
- Understand your Information Worker
RPA Modes of Operation
Attended
· Handles tasks for individual employees
· Employees trigger and direct a bot to carry out an activity
· Employees trigger bots to automate tasks as needed at any time
· Increases productivity and customer satisfaction at call centers and other service desk environments
Unattended
· Automates back-office processes at scale
· Provisioned based on rules-based processes
· Bots complete business processes without human intervention per a predetermined schedule
· Frees employees from rote work, lowering costs, improving compliance, and accelerating processes
How to integrate RPA in your Enterprise
- Information Worker – This is the primary user of the RPA tools. Their manual processes are targets for automation.
- Application Developer – RPA bots change when applications are updated or created. Changes to User Interface require “re-recording” the RPA bots.
- IT Operations – Manage the RPA tools and deploy unattended RPA bots.
Managing Change
- Decrease number of updates to applications and user interfaces
- Decrease number of steps if possible.
- Decrease the number of tools integrated together.
Managing Security
- Find a tool that allows for the injection of security credentials into the RPA bot
- Look at auth keys instead of username and passwords
Managing RPA tools and bots with SecDevOps Workflows
RPA Bundling
SecDevOps Pipelining
Pitfalls of RPA bots
- Security can be a gaping hole if you don’t pay attention to it. One of the biggest mistakes is running applications in an RPA bot in privileged mode or with a “global” account credentials.
- RPAs bots tightly couple to User Interfaces of multiple applications, any small change to an application means you need to re-record the RPA bot.
- RPA bots cannot hand change very well they are very brittle to change in applications and even configuration of applications.
- Reuse is minimal due to the tight coupling with the application user interfaces. Some tools use tags instead of the absolute position of cursor and clicks.
- Some User Interfaces do not allow themselves to RPAs because they are dynamic. Which means they are hard to record.
Tips and Tricks
· Treat RPAs as Complex Services running in your Multi-Hybrid Cloud
· Run you RPA bots through SecDevOps Workflows like other applications.
· Inject Security and Auth at runtime into the RPA tool.
· Find ways to reuse RPA bots in different parts of your organization.
· Have a plan to replace your RPA bot with a simplified integration
· ...
Podcast 1:7 - History and Future of Data Center Architectures
Rise of the Stack Developer
10/29/19 • 21 min
{kind=link}
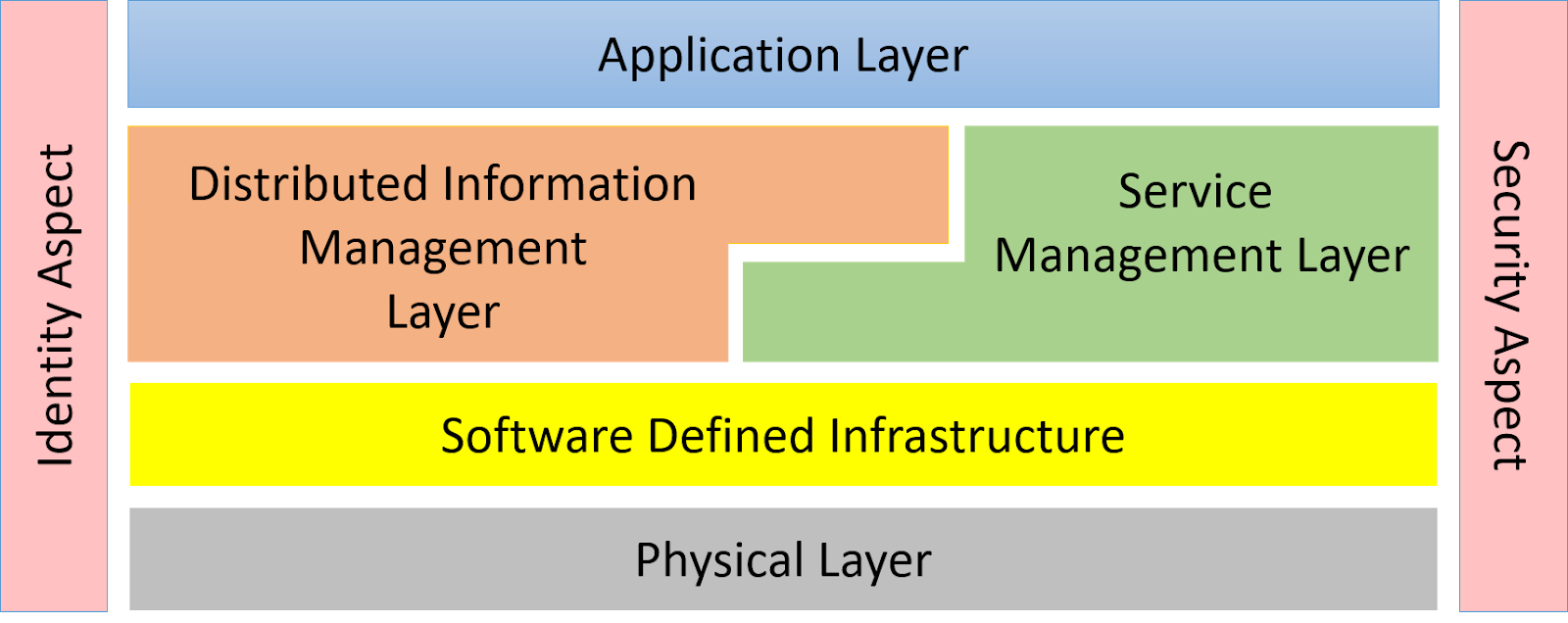
In this episode, the history of data center architecture and application development is reviewed, and the trends of application development shaping the data center of the future. Find out how containers, serverless, and data mesh architectures are being leveraged to decrease deployment times and increase reliability.
Purpose Built Hardware-software Stacks
- Build Hardware based on software stack requirements.
- Long Development Times
- No re-use of technology
- Technology moves too fast
- Hard to integrate with other applications
- Creates technical debt
Virtualization Architectures
- 20 years old technology (VMWare, KVM, HyperV)
- Common Hardware re-use
- Decrease Cost
- Security concerns increase
- Noisy neighbors
Cloud Architectures
- Abstract and simplify Operations
- Common Hardware re-use
- Decrease Cost OpEx and CapEx
- Bursting ability
- Security concerns increase
- Noisy neighbors
- Integration costs
Service and Container Architectures
- Automatic deployment across Clouds
- Optimized OpEx and CapEx
- Fault tolerance
- Easier Integration
- Security concerns increase
- Increased complexity
- Where’s my data
Internet of Things Architectures
- Increase the amount of Data
- Visibility increases
- Security concerns increase
- Increased complexity
- Where’s my data
Data and Information Management Architectures
- Automatic data management
- Data Locality
- Data Governance
- Security concerns increase
- Classification Profiles Not supported
Security and Identity Aspects
- Common Identity (People, Devices, Software)
- Access, Authorization, Authentication
- Detect attacks throughout the ecosystem
- Establish root of trust from through the stack
- Quarantine with reliability
Show more best episodes

Show more best episodes
FAQ
How many episodes does Rise of the Stack Developer have?
Rise of the Stack Developer currently has 8 episodes available.
What topics does Rise of the Stack Developer cover?
The podcast is about Management, Devops, Software Development, Podcasts, Technology and Business.
What is the most popular episode on Rise of the Stack Developer?
The episode title 'Rise of the Stack Developer History' is the most popular.
What is the average episode length on Rise of the Stack Developer?
The average episode length on Rise of the Stack Developer is 22 minutes.
How often are episodes of Rise of the Stack Developer released?
Episodes of Rise of the Stack Developer are typically released every 14 days, 15 hours.
When was the first episode of Rise of the Stack Developer?
The first episode of Rise of the Stack Developer was released on May 6, 2019.
Show more FAQ
Show more FAQ